Sanchit SahaySystems, Virtualization, Web, Cloud and More! | Home | Projects | Blog |
Mon Jul 21 2025 22:29:32 GMT-0400 (Eastern Daylight Time)
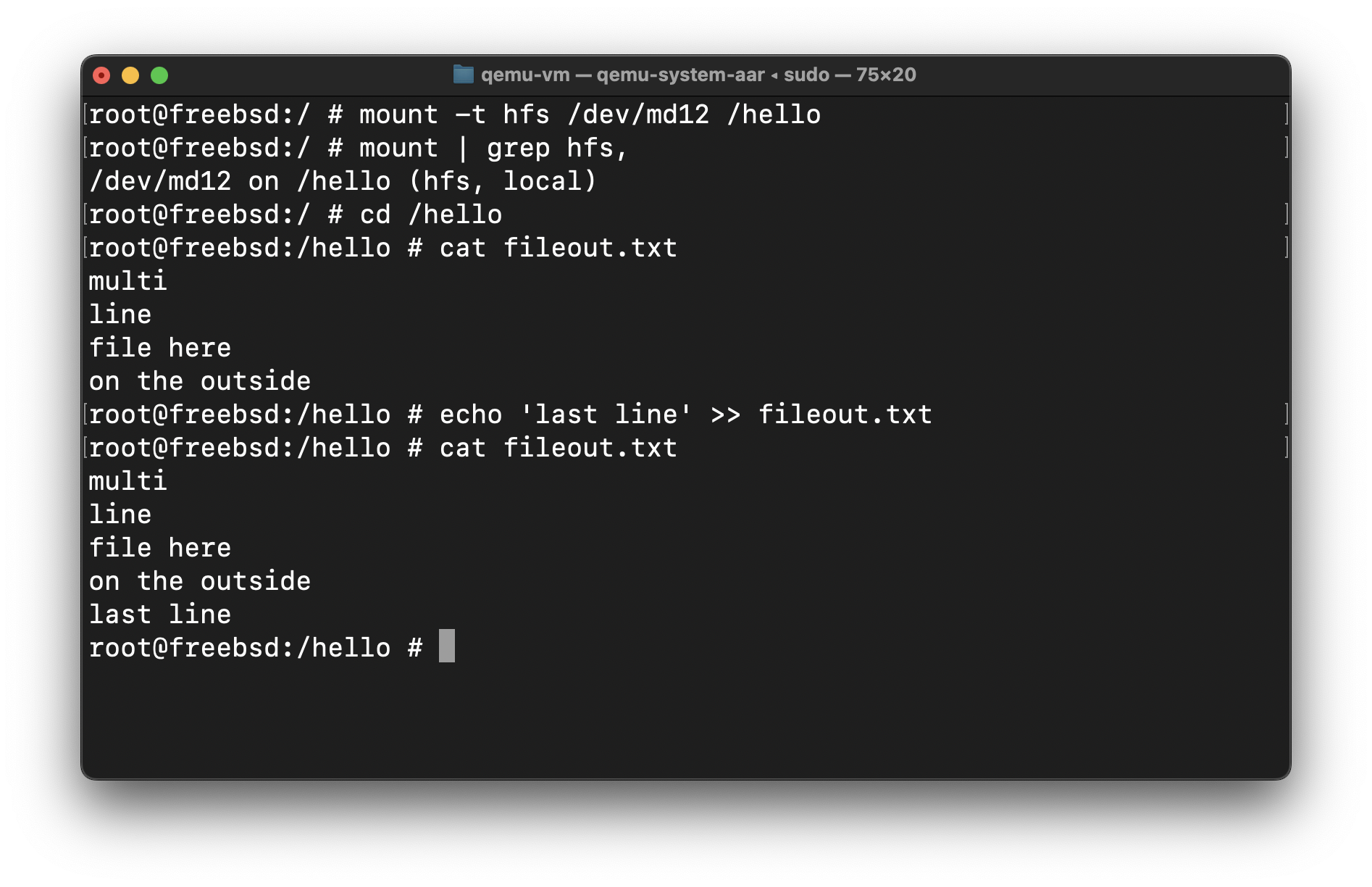
Earlier this year I wandered into a proposal for porting HFS+ to FreeBSD, an endeavor that was attempted once before in the early oughts for FreeBSD 5. When I read through this proposal, I had never heard of the HFS+ filesystem, and had very little technical insights into how FreeBSD worked (or how it differs from other BSDs and Linux), and very little information on how to write a filesystem for it. Naturally, I felt I'd be able to contribute to this project. The only thing in my way was everything, but I reckoned if an infinite number of monkeys can use infinite amount of time to write all of Shakespeare, maybe I could port a filesystem too, after all I am much smarter than a monkey.
As of writing this, the freebsd_hfs port has read and write support without journalling. Through this post I will attempt to take you along my journey, from the top of the "stack frame" to the very bottom, one pop() at a time.
f 0: HFS+, FreeBSD
Let's begin by beginning. (H)ierarchical (F)ile (S)ystem is a now out-of-use filesystem developed by Apple that used to be the default Volume format for XNU/Darwin prior to the introduction of the current APFS filesystem. The '+' at the end indicates a variant of HFS which supports journalling. Today, most places that you see HFS Volumes are old Apple devices like the old-school iPods. If you run macOS, you can create your very own HFS+ image using hdiutil. HFS is natively supported on many other Operating Systems as well such as Linux and NetBSD.
For now it is only relevant to know that XNU/Darwin and FreeBSD share a lot of components in common, and both belong to the wide-and-varied BSD family tree which can find its roots at UC Berkeley's Software Division. The source code for XNU and HFS are open-sourced by Apple.
f 1: Virtual File Systems
The Virtual File System is a standard technique used by Operating Systems that wish to support multiple file-systems. In essence, the VFS allows the kernel to defer the responsibility for the implementation to individual modules for a specific FS. In order for a module to be recognized as a filesystem, it needs to expose a list of standard VOP (vnode operations) and VFS functions. VFS functions handle filesystem level operations such as mounting, unmounting, stats, etc. VOP functions handle vnode specific operations such as reads, writes, links, etc.
Each of these functions have a specific function signature, which enforce the inputs and outputs the function deals with and what the lock state are supposed to be. These are documented in man. For example here's a brief excerpt of man VOP_WRITE which deals with writing data to a vnode.
DESCRIPTION
These entry points read or write the contents of a file.
The arguments are:
vp The vnode of the file.
uio The location of the data to be read or written.
ioflag Various flags.
cnp The credentials of the caller.
LOCKS
The file should be locked on entry and will still be locked on exit.
Rangelock covering the whole i/o range should be owned around the call.
RETURN VALUES
Zero is returned on success, otherwise an error code is returned.
f 2: A kernel module appears
The easiest way to implement a filesystem is through a kernel module. To register our kmod as a filesystem, we use the VFS_SET macro with our vfs function table which lets our kernel know that it has a new recognized filesystem type, and it also handles the init and unload functions for the module.
# hfsplus/hfs_vfsops.c
static struct vfsops hfs_vfsops = {
.vfs_mount = hfs_mount,
.vfs_root = hfs_root,
...
};
VFS_SET(hfs_vfsops, hfs, 0);
------
We also need to register our VOP function table.
# hfsplus/hfs_vnops.c
struct vop_vector hfs_vnodeops = {
.vop_default = &default_vnodeops,
.vop_close = hfs_close,
.vop_mkdir = hfs_mkdir,
.vop_open = hfs_open,
.vop_read = hfs_read,
...
}
VFS_VOP_VECTOR_REGISTER(hfs_vnodeops);
------
As long as our functions have the appropriate signature and return an appropriate return code, the kernel will be happy and shouldn't panic.
f 3: So about that port
To actually make these functions, well, functional, we need a few things.
1.We need a way to actually read and write data onto disk.
2.We need to populate these functions to call these read/write methods, which also populate the correct structs and return the correct codes.
As you can probably guess, writing all of this from the ground up is a monumental feat, which requires a much higher level of craft and attention to detail. Luckily for us, this is where the open-sourced HFS source code and XNU's shared bloodlines with BSD come in handy for us.
To begin with 1., the hfscommon folder contains a bunch of standalone util functions which can take raw data and offsets, and convert them into BTree blocks which are readily traversable.
And for 2., Given that shared bloodline, most changes from XNU to BSD where fairly trivial - in most cases the core data-flow and operations remained the same, and some tweaks were required to adapt to FreeBSD's VOP_ or VFS_ function signatures.
Most of this work was already done by yars' port, however this was done for FreeBSD 5. Most if not all the VFS/VOP functions have since changed. Let's list some of these in a rapid fire round:
- VOP_ functions don't take a
threadargument anymore. - VOP_UNLOCK and several other functions do not need the flags the LOCK was set with.
- XNU had different signatures for MALLOC and FREE.
- To get sectorsize and mediasize, use geom APIs instead of IOCTL.
- Use insmntqueue() to register a vnode.
- Changing int32 pointers, and pointer arithmetic.
f 4: You listed a thousand keywords, weren't you new to this?
Yes, nothing I said would have registered to me had I read it before working on this project, and nothing I say will elucidate what they are actually meant to mean. The only useful analysis I can provide is an account for my journey, how I figured out what was wrong, what needed fixing, and where to even to start.
f 5: Let's begin by beginning, a second time
Working on this project was pretty nebulous, unlike most of my prior experiences there was no neat little documentation page to copy-paste some code from to get started, neither were there a thousand guides on the do's and dont's, or even a blog post trying to build something that was exactly like what I was building. For the most part, I was on my own, I had nothing apart from a compiler, a debugger, a bunch of manual pages, the source code for a bunch of different filesystems already integrated in the FreeBSD kernel, and a really helpful mentor, and a pretty active mailing list. As I said, all on my own.
Here's the general flow I followed over the course of this project:
- First, create a generic stubbed function which does nothing more than logging what function was called.
# hfsplus/hfs_vnops.c
static int
log_notsupp(struct vop_generic_args *ap)
{
if (ap->a_desc && ap->a_desc->vdesc_name) {
printf("Unimplemented vop: %s\n", ap->a_desc->vdesc_name);
} else {
printf("Huh?\n");
}
return (EOPNOTSUPP);
}
------
- Second, try to invoke a filesystem operation. For example - mount, or ls. Take a note of which function were called. This gives you a general idea of the entry and exit points for any given fs operation.
- Third, copy the function from the old port, wrestle with compiler warnings, linker warnings and kernel panics.
- Go back to step 2, repeat until you are stuck, or until the operation does what it is supposed to.
The issues I ran into where of the following nature for the most part:
1 The compiler tells you that a function expects different signatures. This was helpful with knowing that functions like VOP_WRITE, VOP_LOCK, VOP_UNLOCK etc. take fewer arguments than they used to.
2 The compiler tells you that a function does not exist, this lets you know that the canonical way to achieve something has changed. Consult a different FS code to see what.
3 The linked complains, this just means (for e.g.) that hfs_mount requires certain utility features that you haven't yet implemented.
4 The compiler gives you the go ahead, the linked is satisfied, you load your module, run an operation, and bam - a kernel panic. These are the best possible way for your kmod to fail, because it gives you an exact code line of where the panic occurred, and it's easier for you to know what failed, and the state of your system at the time it failed.
5 The compiler is okay, the linker is okay, you run an operation there is no panic. You wait, your system crashes out of the blue, or it prevents you from performing a different unrelated feature. This likely means that you have broken some rule for a vnode lifecycle. The best thing to do here is to read a different filesystem code to see how your approach and their approach differs. The second thing to do is to make sure you are honoring all the lock rules for your given function.
Doing this, one fs feature a time, one kernel panic at a time, you slowly start to get the flow of why things are where they are, what they are supposed to be doing, and why they do it the way they do it.
Of course, there will be times where you will be completely stumped, in times like these you need two things - 1., an understanding of what is actually going wrong, and 2., a detailed report of this for you to ask someone on the fs-mailing list. I've found this group to be extremely prompt and insightful, in many cases they not only fixed the problem I was facing at the time I posted it, but also anticipated future issues I would run into.
f 6: hold on, where are the guardrails? how do you inspect a random coredump?
If you are like me, reading the 6th point in the last paragraph might have caused you some unease. If your kernel module can cause a system-wide crash well after your supposed operation ran, how do we ever ensure that our kernel is stable? Surely it's impossible to detect these issues during a code review. Second, if these panics are occur after your functions have exited, how do we know what exact thing caused this panic? And how do we know what the panic actually means? Again, it seems impossible to detect any of this without having to do an insane amount of work.
Lucky for us (I guess lucky for me), the world is full of people smarter than me who took care of stuff like this. In this section I'm briefly going to talk about a few kernel features that I used to overcome these issues.
- options INVARIANTS
When you run a debug build of the FreeBSD kernel, you can enable INVARIANTS on it. What this option does is run thousands of runtime checks to ensure that each function enters and exits with the state of the system in a cohesive state. This ensure your kernel panics if these checks don't pass. This is helpful to us because if suppose you hfs_write function mishandles a lock, instead of waiting for a butterfly's wing to flap in order for the system to panic, it panics immediately as it enters or exits your function, pointing you to a very specific place for you to go debugging.
- options WITNESS
This flags builds your kernel such that it keeps track of lock order of your vnodes. It performs runtime assertions which ensure that your locks are being acquired and released in the correct order, minimizing the chances of potential deadlocks.
- options VFS_DEBUG_LOCKS
This comes in handy when you are debugging a lock violation, it lets you see exactly where a lock was acquired, and who holds it. Combined with the the other two options above, it really helps to narrow down where your code went wrong.
f -1: parting thoughts
Hopefully, over the course of this summer you will see several updates to this blog post, as I work on the second half of this project which is to enable journalling support.
Prior to starting this project, I had very little idea of how kernel development actually worked. While I had taken an OS class in undergrad, it left me with little more than a theoretical understanding of how things are supposed to work. Prior to this, I also had very little experience working with C, for most of my life I've bounced between Python, JS, and Rust.
If you made this far, it is only appropriate that I try to give you pocketable condensed takeways I had from this experience.
First, it reminded me that the only way to learn anything daunting is by doing it. The only thing I regret is not doing something like this sooner. Just a few months ago nothing I've written in this blog would have made sense to me.
Second, the knowledge passed through lore is there for you to access it. I mentioned before that unlike a simple React application, there aren't troves of accessible and readily available guides for you to follow. Rather, it forces you to actually figure out what it is that is going wrong with your system, convert into a meaningful blob of text, and ask people who know better.
And finally to satisfy the rule of threes, it is always more about the journey than the destination. While technically speaking the only thing I'm working on is porting a filesystem, the sheer act of starting on such a project required me to actually learn a lot about so many other things. Half the times I tripped and fell, it was not because there was an issue with the hfs code, it was because I hadn't taken into account a completely different thing while running my code. It also gave me a much deeper insight into why C behaves the way that it does. I also never understood why so many OS devs held such deeply rooted opinions they would die for, I now totally see why there are a thousand variants for both BSD and Linux.
More than anything, it also reaffirmed my love for systems.